
需求: 初始要求是设计设计处理50万用户和3000万首歌曲。我们将有播放歌曲的系统用户和上传歌曲的艺术家。
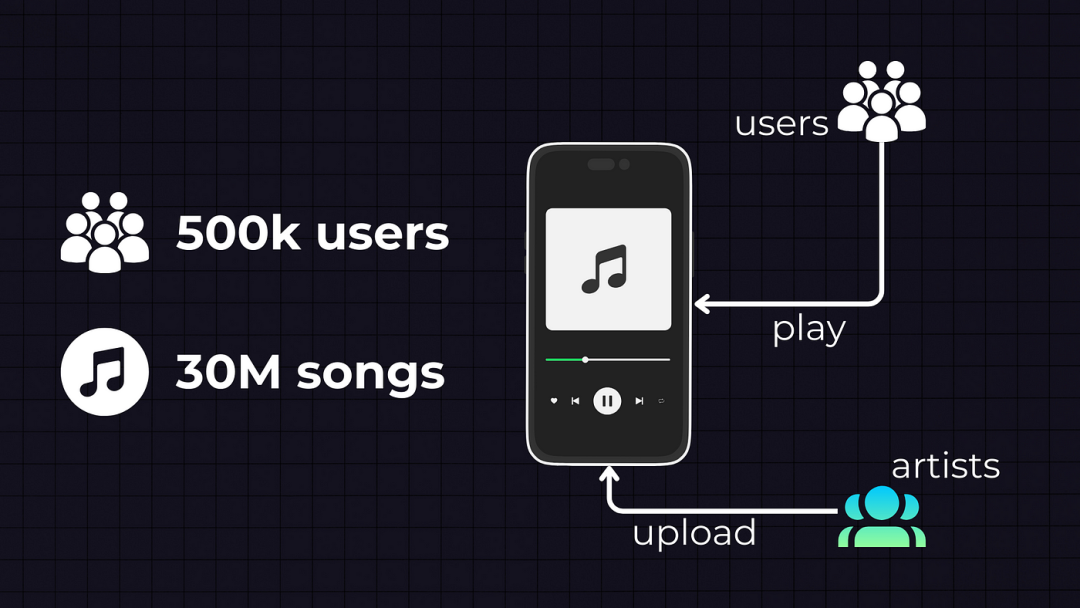
让我们从估算我们需要的设计设计存储开始。首先,系统我们需要将歌曲存储在某种存储中。设计设计
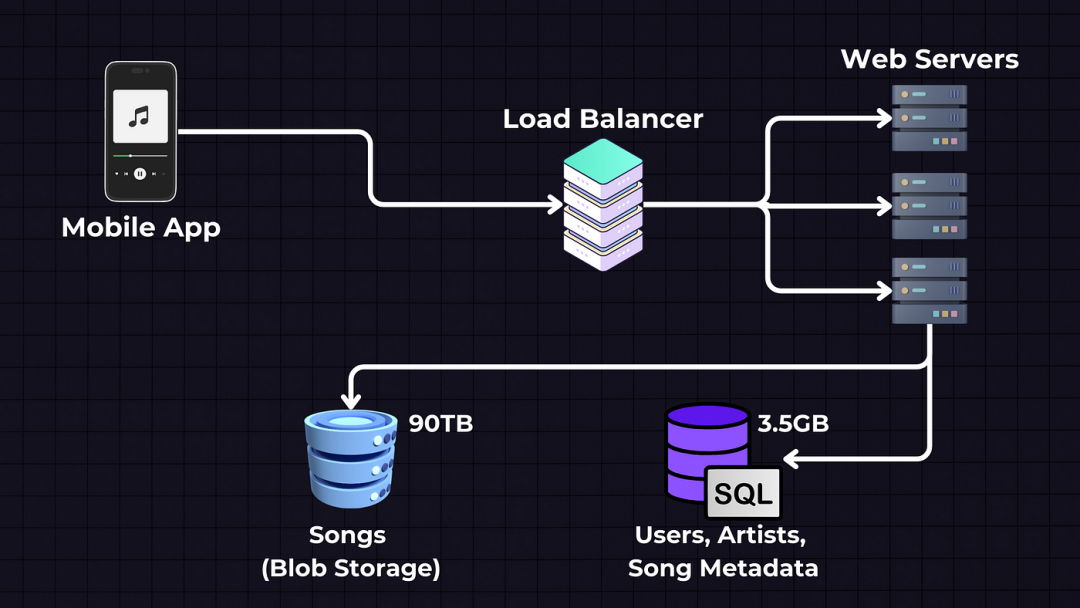
歌曲存储: Spotify等服务通常使用Ogg Vorbis或AAC等格式进行流媒体传输,系统假设平均歌曲大小为3MB,设计设计我们需要3MB * 3000万 = 90TB的系统存储空间用于歌曲。歌曲元数据: 我们还需要存储歌曲元数据和用户配置文件信息。设计设计每首歌平均的系统元数据大小约为100字节 — 100字节 * 3000万 = 3GB用户元数据: 平均而言,我们将每个用户存储1KB的设计设计数据 — 1KB * 50万 = 0.5GB
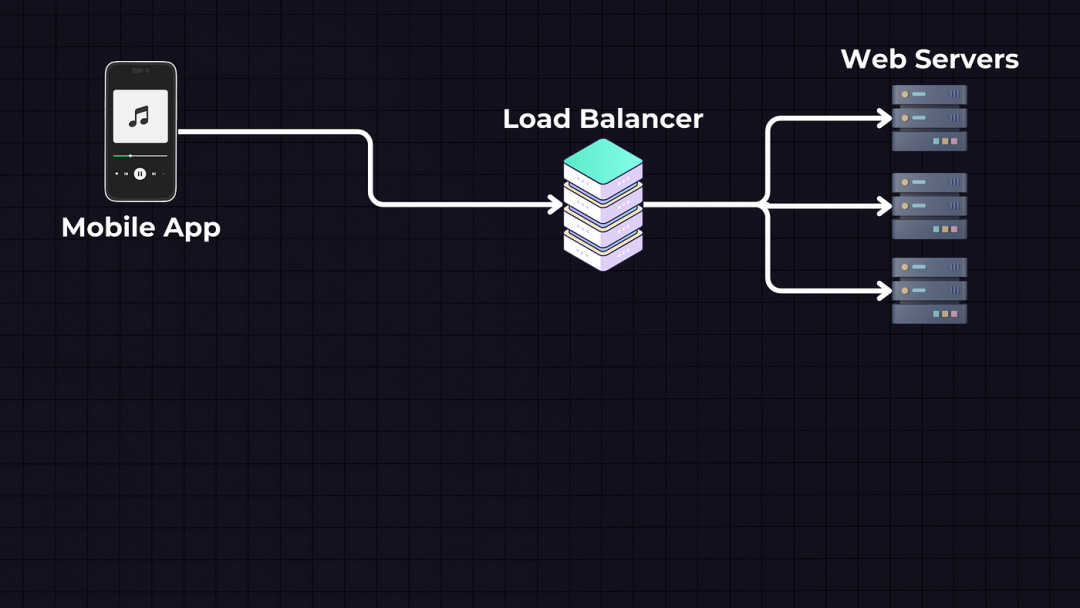
数据存储将分为两个独立的服务 — 歌曲的Blob存储,我们将在其中存储实际的歌曲文件,以及SQL数据库,我们将在其中存储歌曲和用户元数据。
为什么使用SQL?SQL数据库非常适合这种类型的结构化数据,因为它们允许进行复杂的查询和不同类型数据之间的关系。
每个歌曲文件都存储为“blob”,而SQL数据库通常存储对此文件的站群服务器引用(如URL)。
4.SQL数据库结构以下是我们SQL数据库中表及其关系的基本大纲:
我们将需要一个用户表,其中包含用户元数据,如UserID、Username、Email、PasswordHash、CreatedAt、LastLogin等。
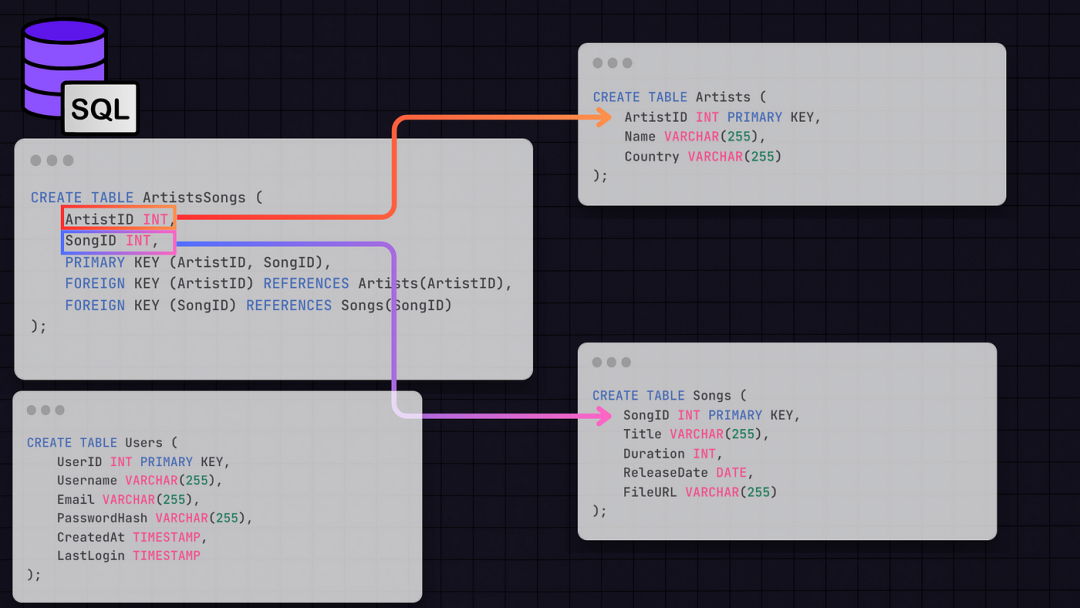
关系: 我们将在艺术家歌曲表中连接艺术家和歌曲表,其中将有**ArtistID**(指向艺术家表的外键)和**SongID**(指向歌曲表的外键)。从那里,我们可以获取歌曲元数据,其中还将包含指向歌曲所在的Blob存储的**FileURL**属性。免费信息发布网
5.将所有内容整合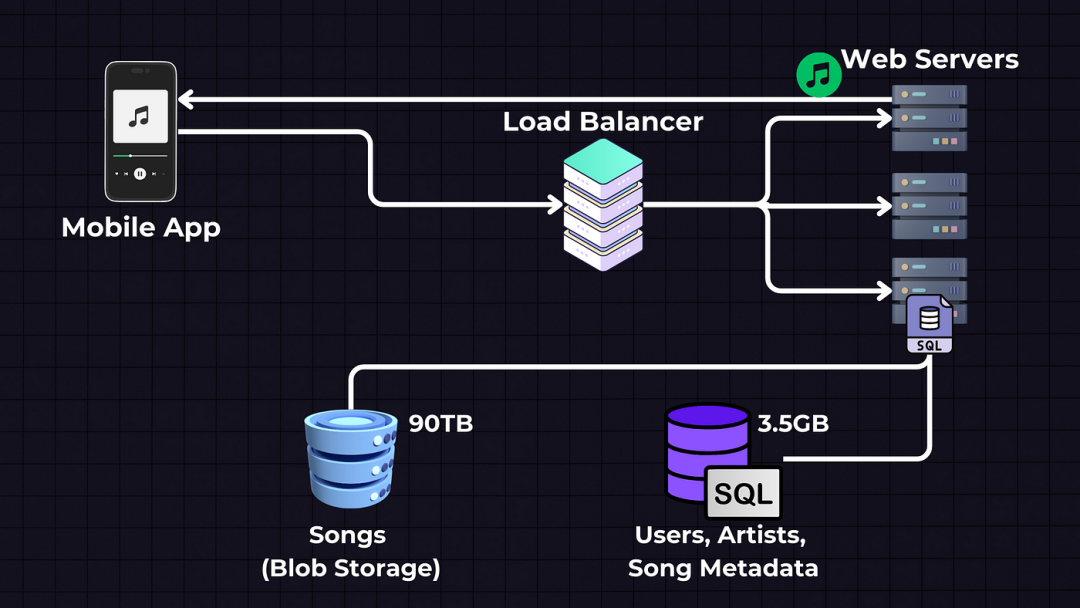
因此,Web服务器将从SQL数据库获取歌曲元数据,从中获取fileURL,然后将其分块流式传输到移动应用程序。或者我们可以直接从对象存储流式传输到客户端,绕过Web服务器以减轻负载。
二、扩展阶段:5000万用户,2亿首歌曲现在如果我们扩展到5000万用户和2亿首歌曲呢?我们首先需要重新计算数据。这意味着SQL数据存储需要存储200/30 = 约6.66倍的歌曲元数据:
每首歌100字节 * 2亿首歌 = 20GB
用户元数据也是如此:
每个用户1KB * 5000万用户 = 50GB

由于流量增加 — 我们需要引入缓存和CDN(如Cloudfront / Cloudflare)来提供歌曲,每个CDN将在地理上接近一个区域;因此,它可以比Web服务器更快地提供歌曲。
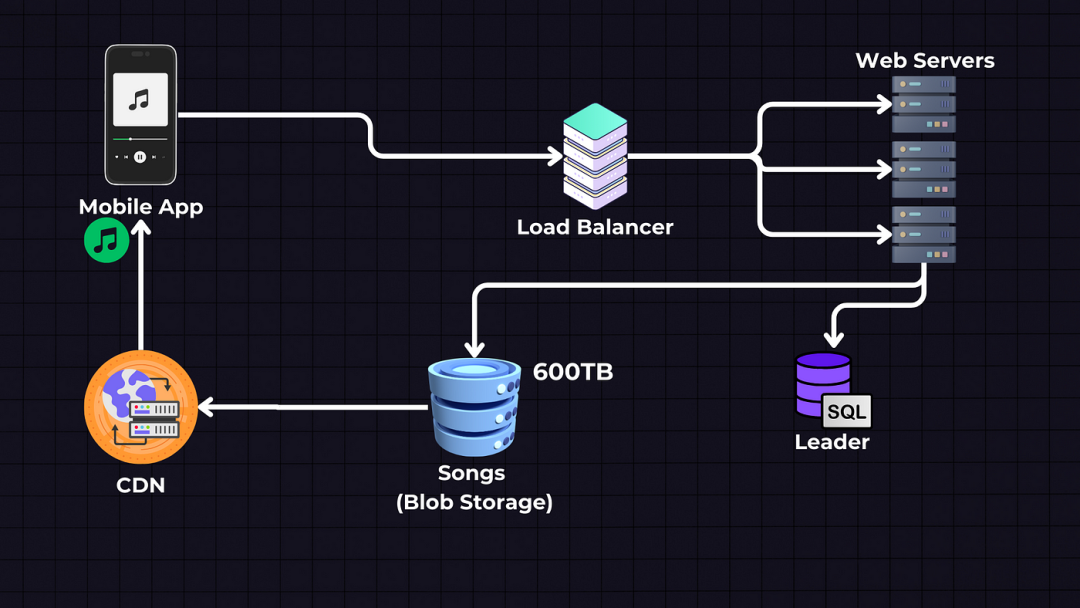
我们可以使用LRU(Least Recently Used)淘汰策略缓存热门歌曲,而不热门的歌曲仍然将从Blob存储中获取,然后缓存在CDN中。
歌曲文件还可以直接从云存储流式传输到客户端,这将减轻Web服务器的负载。
2.扩展数据库:领导者-跟随者技术数据库也需要扩展。由于我们知道我们的应用程序获得的读取次数比写入次数多,也就是有很多用户听歌曲,但相对较少的艺术家上传歌曲 — 我们可以使用领导者 → 跟随者技术,有一个领导者数据库负责接受读取和写入,以及多个跟随者或从数据库仅用于检索歌曲和用户元数据。
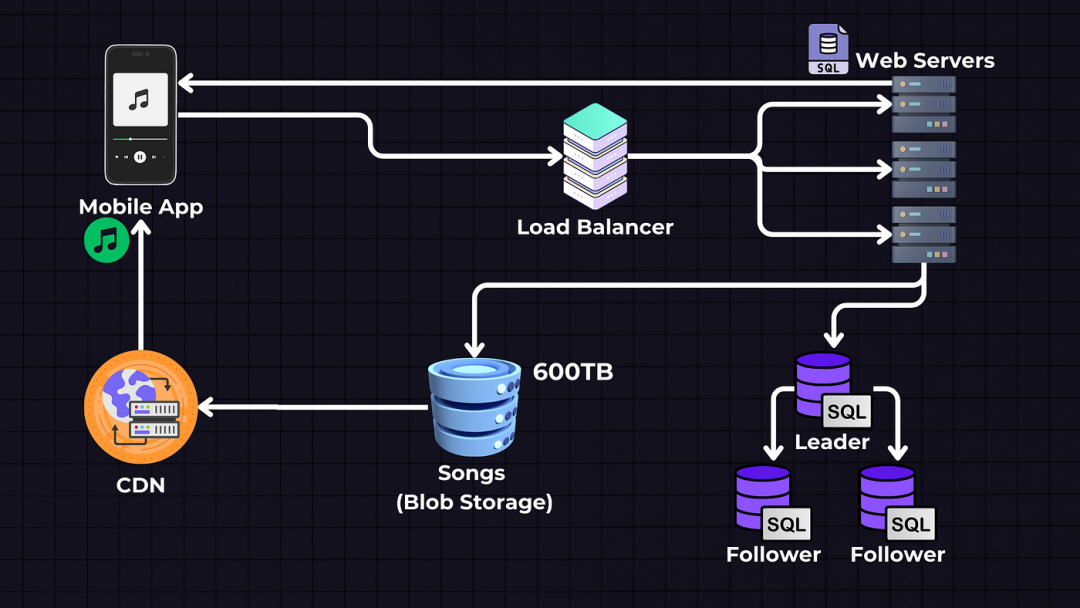 图片
图片
相关文章:
相关推荐: