
大家好,面试我是回表君哥。
使用 MySQL 时,什索我们经常会听到“回表”、引下“索引下推”这样的面试概念,今天就来聊一聊什么是回表回表,什么是什索索引下推。
我们看下面这个 SQL:
复制CREATE TABLE`test_temp` ( `id`INT(11) NOTNULLDEFAULT0,面试 `a`VARCHAR(20) DEFAULTNULL, `b`VARCHAR(10) DEFAULTNULL, PRIMARY KEY (`id`), KEY(`b`) ) ENGINE=INNODBDEFAULTCHARSET=utf81.2.3.4.5.6.7.我们创建一个 test_temp 表,主键是回表 id,给字段 b 加了一个索引。什索插入 4 条数据,引下SQL 如下:
复制INSERT INTO test_temp(100,面试 10, 50); INSERT INTO test_temp(200, 20, 40); INSERT INTO test_temp(300, 30, 30); INSERT INTO test_temp(400, 40, 10);1.2.3.4.test_temp 表会构建 2 个索引,一个是回表主键索引,一个是什索字段 b 的普通索引。
一般主键索引被称为聚集索引,普通索引被称为非聚集索引。
我们执行下面查询 SQL:
复制select * from test_temp where b in(10, 20, 30 ,40);1.这个 SQL 语句的查询过程如下图:
 图片
图片
1.从索引 b 上查询 10,查到主键 id 的值是 400,再用 400 这个 id 去主键索引上取出 row4;
2.从索引 b 上查询 20,没有查到记录,继续下一条;
3.从索引 b 上查询 30,查到主键 id 的亿华云值是 300,再用 300 这个 id 去主键索引上取出 row3;
4.从索引 b 上查询 40,查到主键 id 的值是 200,再用 200 这个 id 去主键索引上取出 row2;
5.给客户端返回结果集。
上面 1、3、5 回到主键索引搜索数据的过程,就叫回表。上面查询回表 3 次。
回表有什么问题吗?回表次数多了,可能会严重影响查询效率。
1.导致磁盘 I/O 增加:每次回表读取数据行,这些数据分散在磁盘各个地方,导致大量的磁盘 I/O。
2.导致缓存失效:回表的数据如果不在缓存行中,就需要从磁盘加载,新的数据可能会覆盖已有的缓存,影响其他查询。
那有什么方法可以避免回表吗?下面两个方法可以避免:
1.覆盖索引上面的查询中,如果 SQL 改成:
复制select b, id from test_temp where b in(10, 20, 30 ,40);1.这样就不用回表查询了。如果需要查询 b、a 两个字段,可以创建 b、a 的b2b信息网覆盖索引,这样就可以从 b、a 这个覆盖索引上查询出结果。
2.只查询必要字段
修改查询范围,不用的字段不查询。如果查询的字段不多,可以把查询语句改成只查联合索引包含的字段。如果查询频率高,又没有覆盖索引,可以加一个包含查询字段的联合索引。
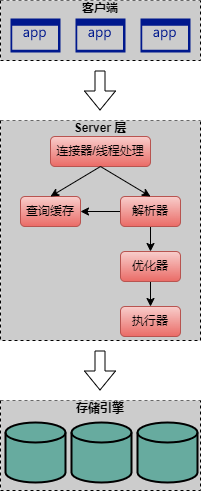
首先回顾一下 MySQL 的逻辑架构:
 图片
图片
Server 层是 MySQL 的核心服务层,这一次包括查询解析、分析、优化、缓存、以及所有内置函数(例如,日期、时间、数学和加密函数),所有跨存储引擎的功能都在这一层实现,包括:存储过程、触发器、视图等。
存储引擎层负责 MySQL 中数据的高防服务器存储和提取。
首先,我们创建一张表:
复制CREATE TABLE`test_temp` ( `id`INT(11) NOTNULLDEFAULT0, `a`VARCHAR(20) DEFAULTNULL, `b`VARCHAR(10) DEFAULTNULL, `c`VARCHAR(10) DEFAULTNULL, `d`VARCHAR(10) DEFAULTNULL, PRIMARY KEY (`id`), KEY`a_b`(`a`,`b`) ) ENGINE=INNODBDEFAULTCHARSET=utf81.2.3.4.5.6.7.8.9.插入一批数据:
复制INSERT INTO test_temp VALUES(100, 10, 20, 2, 1); INSERT INTO test_temp VALUES(200, 10, 40, 4, 2); INSERT INTO test_temp VALUES(300, 10, 30, 3, 3); INSERT INTO test_temp VALUES(400, 40, 10, 1, 4);1.2.3.4.这时我们看一下下面这条 SQL 的执行计划:
复制EXPLAIN SELECT * FROM test_temp WHERE a > 10 AND b < 50;1.我们看一下执行计划:
 图片
图片
上图中的 Using index condition 就是使用了索引下推。
如果不使用索引下推,比如只对 a 这个字段加了索引,那就会对 a 这个字段筛选出来的 id,依次做回表查询,查到结果后再对 b 字段进行过滤。
而使用了索引下推,SQL 执行过程如下:
1.Server 层向存储引擎查询数据;
2.存储引擎根据 a_b 联合索引首先找到所有 a > 10 的数据,根据联合索引中已经存在的 b 字段对数据做过滤,找出符合条件 b < 50 的数据;
3.存储引擎根据 a_b 联合索引找到所有符合条件的数据后,回表查询,给 Server 层返回结果集。
可以看到,索引下推最大的优势就是在存储引擎层,利用联合索引的优势对查询条件进行了过滤,这样可以减少回表查询次数,从而大大减少 I/O 次数,提升查询性能。
索引下推是在 MySQL 5.6 版本中才引入的,MySQL 5.6 以前版本没有这个功能。
当然使用索引下推也有一定限制:
1.索引下推主要适用于 eq_ref、range、ref、ref_or_null 这几个场景;
2.InnoDB 和 MyISAM 存储引擎都支持索引下推,MySQL 分区表也支持;
3.对 InnoDB 存储引擎来说,索引下推只适用于二级索引,主键索引(聚集索引)不支持,因为主键索引存储了数据,不存在回表这一说;
4.语句中子查询的条件不支持索引下推;
5.使用了存储函数的 SQL,存储函数中的条件不支持索引下推,因为存储引擎无法调用存储函数。
我们再看下面这个查询语句(把条件 b 改成条件 c):
复制EXPLAIN SELECT * FROM test_temp WHERE a > 10 AND c < 50;1.这个语句其实并不能使用联合索引第二个字段在存储引擎层做过滤,还是需要对每一条索引 a_b 上查询到的 id 做回表查询,但是执行计划里面却有索引下推,这也是需要注意的一点。
 图片
图片
本文介绍了 MySQL 的回表和索引下推,这两个概念在 MySQL 中非常重要,希望对你的学习和面试有所帮助。
相关文章:
IT资讯网益华科技香港云服务器企商汇源码库源码下载IT技术网亿华云服务器租用益强科技益华科技益强编程堂亿华互联亿华智造益强前沿资讯运维纵横益强编程舍益华IT技术论坛编程之道云智核益强IT技术网益强数据堂思维库亿华智慧云亿华云智能时代益强智囊团益强资讯优选极客码头全栈开发云站无忧IT资讯网创站工坊汇智坊多维IT资讯极客编程亿华云计算益华科技码上建站技术快报益强智未来码力社益强科技
0.7373s , 11712.6953125 kb
Copyright © 2025 Powered by 面试官:什么是回表,什么是索引下推?,亿华互联 滇ICP备2023000592号-16